


I just wrote my life’s longest blog post title! If you are reading this blog post, I would expect you to be either in the field of data science / NLP or interested in birding! If you are not, you might be bored to death. This post talks about, as the title suggests but I would need to write it one more time for SEO benefits – Natural Language Processing (NLP) techniques on user-generated small texts (mostly tweets, fetched based on a search phrase used mostly by Indians) to detect names of birds by building a custom Named Entity Recognition (NER) model based on Spacy. It also outlines the problems faced while working with such data and a possible ensemble model to get the best results, given the current restrictions.
Summary
In this blog post, I discuss the issues one might face while trying to detect bird names in user-generated texts over social media, the challenges of such user-generated content, the challenges of a rule-based system, and I propose a custom Named Entity Recognition (NER) model based on Spacy, trained on tweets pulled from Twitter using the hashtag #IndiAves. I try to compare the rule-based methods with that of custom NER but that seems a little incomplete to me. I have tried to be as scientific as possible, but please realize this is not a scientific paper.
Skip to the model.

Problem Statement:
There is no existing Python package / Named Entity Recognition (NER) model to recognize bird names from text input.
Related Work:
When it comes to identifying birds using Artificial Intelligence (AI), there has been a substantial amount of work done in image processing and audio processing. It is pioneered by Cornell Lab of Ornithology, the creators of the eBird platform which crowdsources bird photographs, metadata of sightings, and other details. They launched the Merlin App and the BirdNet app to identify birds using images and audio clips respectively. Some fascinating work is done in the area of audio processing using AI which ranges from decluttering bird songs to predicting the bird’s next song.
In the area of Natural Language Processing to identify birds, is rather underexplored, to say the least. I found Dr. John Harley’s post on custom NER on bird Taxonomy using Spacy. I found it useful and his work is the foundation of the work that I present in this blog post.
Challenges related to user-generated texts :
As students of Natural Language Processing (NLP), we love and hate the nuanced use of a particular language across various domains of work. Previously, I have dug into legal texts, clinical notes & other medical texts, and international student inquiries about a university course. The experience I previously gained, assisted me in this task! There are spelling mistakes, short hands, implications, ambiguity, and whatnot. So here are a few of the challenges one has to face while detecting bird names from user-generated texts.
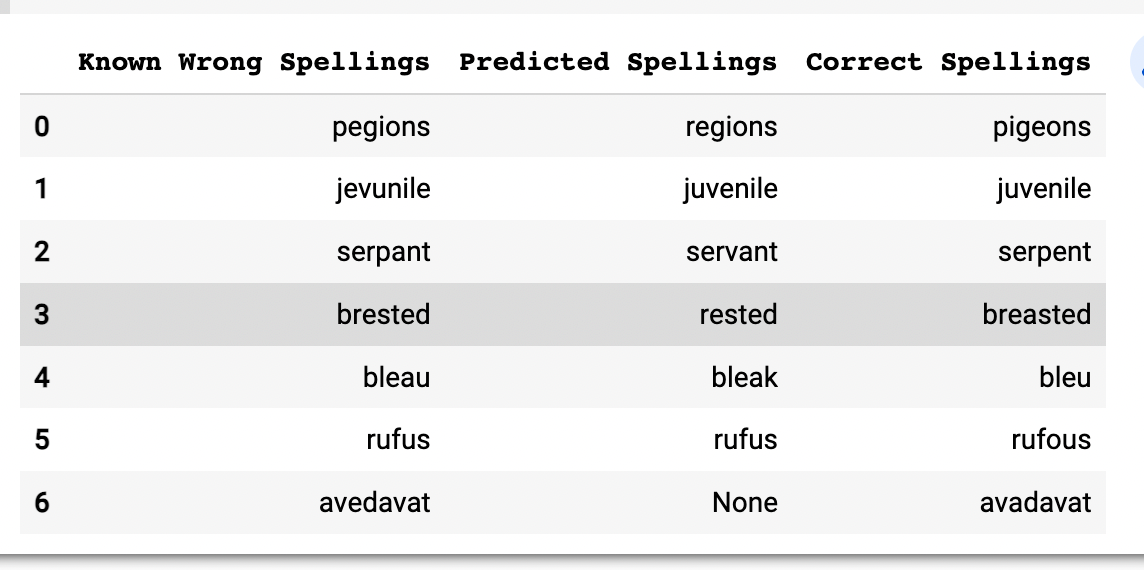
- Spelling mistakes: Users have made spelling mistakes which include using “pegions”, “jevunile”, “serpant”, “brested”, “bleau”, “rufus”, “avedavat” instead of “pigeons”, “juvenile”, “serpent”, “breasted”, “bleu”, “rufous”, “avadavat”. Such spelling mistakes, which stem from the way people pronounce words are not uncommon among non-native English speakers. This has to be expected.
- Generic mistakes: These too are not uncommon among people, when they do not have formal training in Ornithology; that’s basically most enthusiastic bird watchers. Let me give fancy names to the problems!
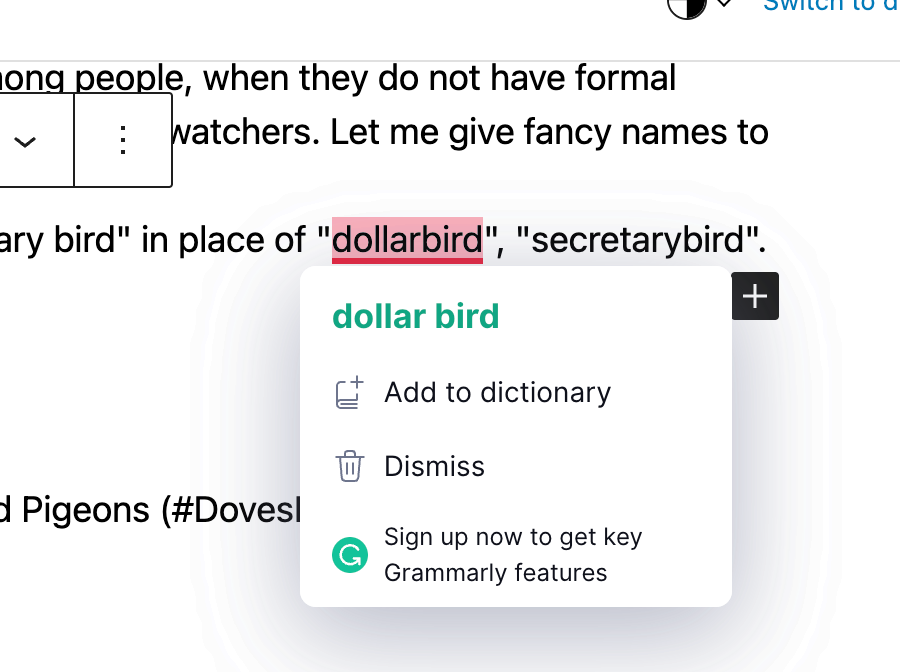
- Why Not Space?: “dollar bird”, “secretary bird” in place of “dollarbird”, “secretarybird”. Even Grammarly suggests a space in the middle, because why not? Check Fig 1.
- The Goose-Geese problem: Grammatically, the plural of a Goose is Geese. We will discuss the problem in the later section.
- Gendered name problem: A Peacock is a male. The Peahen is the female. But the official name is Indian Peafowl (male/female).
- Munia-Munias problem: It is a general practice to add “s” after a bird’s name to denote the plural. It might always not be the correct way to denote the plural, and further if we are matching names with a curated list, it might not match.
- Others: Mentioning “Open billed”, ” in place of “Openbill”, and “bayaweaver” in place of “Baya Weaver”.
- Why mention the obvious? One user mentioned, “thick billed pigeon” instead of “thick billed green pigeon”. I am not sure if all thick billed pigeons are green pigeons.
- Implied names / Ambiguity:
- Based on context: In a discussion of Doves and Pigeons (#DovesNPigeons), when someone reports having seen “the yellow footed one”, they refer to the Yellow-footed Green Pigeon.
- Based on the region: When someone from India mentions “Open Billed stork”, they are very likely to imply “Asian Openbill”, or “peacock” they very likely mean “Indian Peafowl (male)”.
- Based on the entire presentation: The text accompanying photographs of Red Munia mentions only “munia”. When the text is separated from the image, it is a little ambiguous to figure out whether the user is mentioning Red Munia or Scaly-breasted Munia, or Tri-coloured Munia.
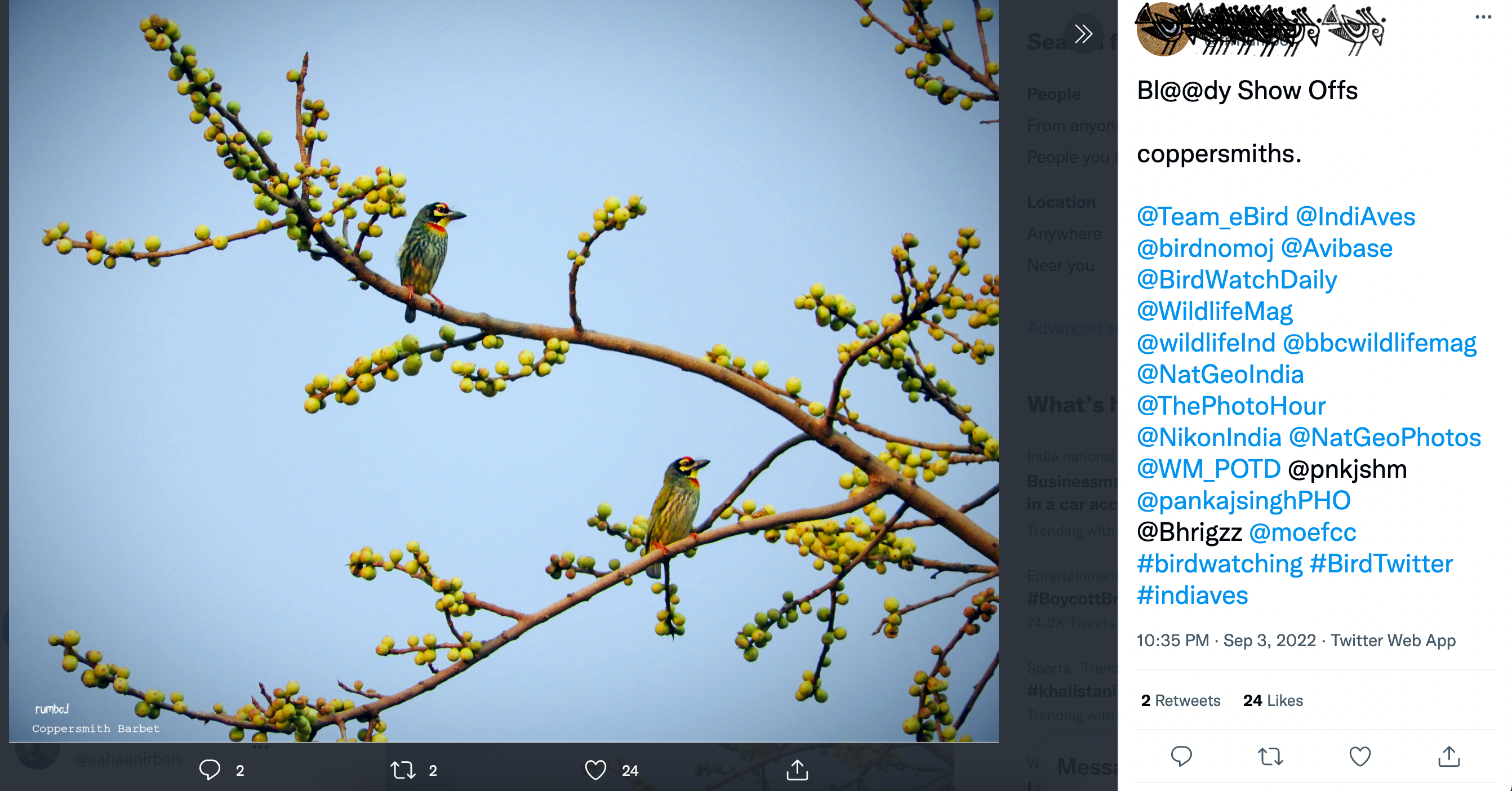
- Colloquially accepted terms: At least one user has used “Thick billed pigeons” instead of “thick-billed green pigeon”, “Coppersmiths” instead of “Coppersmith Barbets”, “Himalayan Griffon” instead of “Himalayan Griffon Vulture” or “Himalayan Vulture” or “Griffon vulture”. While thick-billed could also be thick-billed ground pigeons if you are in New Guinea, the user is based in India.
- Alternate names / (less) Ambiguity: “Lesser Golden-backed Woodpecker” finds a mention, but it does not occur in the curated list. A little search over Google suggested that it is the Black-rumped Flameback.
- Missing names / Hashtag: While the description text described Emerald Dove, the name found a mention only in the hashtag which was #EmeraldDove. Many users just mention the bird name(s) as hashtags.
- Use of emoticon inside a bird name: At least one of the users used the “eyes” emoticon to denote “Indian white eye”; refer Fig 3 below.

Approaches and Challenges:
Approach 1: Make a curated list of birds from the resources like this, and if a bird name from the curated list of birds appears in the text, take note of it and return the value.
Challenges in Approach 1: This approach, in theory, seems to be the best, albeit the easiest, but the general issues with user-generated texts, make this approach a little too challenging. If there is a spelling mistake, a space in between, or an implied name or “geese” when mentioning “Bar-headed Goose”, then the name from the list does not match the user-generated text.
One idea was to detect mistaken spellings and replace them programmatically with correct spelling. In the previous section, I mentioned some wrong spellings, I tried exactly the same spellings to check. I used a generic spell checker for English words and I think it is safe to say, it would not work. Check out Fig 2 for the results. Maybe if we have word embeddings trained on a lot of texts related to Ornithology, it might so I would keep this for future work.
Approach 2: The second approach is to train a custom Named Entity Recognition (NER) model, using an open source library, Spacy. It would be a Machine Learning / Deep Learning based model that, when trained over user-generated data should take care of the nuances of the data.
Challenges in Approach 2: Machine Learning models require a good amount of labeled data to train them. Even if we have a good amount of relevant data, it would have its share of issues, like over-representation of common birds and under-representation, if at all, of rare birds. In a later segment, I would discuss the dataset and its challenges of the dataset. The challenges to this approach mainly revolve around data, labeling, and training using the data. The final model will have a certain amount of biases that would stem from the nature of the data we collect. Given that we are dealing with a simple and apolitical problem such as detecting bird names, I do not think the bias would have much of an impact.
False positives: When trained with “black kite”, “red kite”, “brahminy kite”, the model identifies “huge kite” as a bird in the sentence, “A huge kite flew over my head”. It identifies “famous kingfisher” as a bird species in this tweet. Similarly from a tweet that mentioned “a golden yellow glow from leaves”, the NER model predicted “golden yellow” as a bird, maybe because one of the training examples had a Golden Oriole! Similarly, the model predicted “International Vulture” as a vulture.
Description of the dataset:
Preprocessing steps:

Limitations of the custom NER model:
- I did a boo-boo. I trained the model to identify just bird names. So what went wrong? People “sight” birds. People “sight” tigers. But Tigers are not birds. Please check Fig 3. We can rectify this by training the model on a larger dataset differentiating between wild animals and birds. Let’s put that future work.
- It does generate an insignificant amount of false positives. It can not be ruled out that it is a possibility that what the module returns is not correct.
Limitations of the dataset: I am not describing the dataset here. I would however mention the main limitation of the dataset. The tweets are fetched using the hashtag #IndiAves, which is used in mostly urban circuits in India. The spelling mistakes, grammatical mistakes, and context are mostly South Asian in nature. While this model works significantly better with Indian English, I am not sure if it would be as good when it faces English used in other countries (other than the UK, and the USA).
Approach 3: Like any student of data science would suggest – an ensemble model! So the input passes through one bucket which works on approach 1, and if it fails which is not unlikely, the second bucket predicts the bird name using approach 2. In case it fails the ensemble arrangement, which also should not be surprising given that we have significantly less training data, we should work towards bettering the ensemble method unless, of course, we hit something better!
But is there a need?
I ran the ensemble method on three sets of data, pulled from Twitter using hashtags. For approach 1, I used a list of birds fetched from Wikipedia and the eBird portal. For approach 2, I used the custom NER model I proposed.
| Hashtag | Instances (total) | Instances (birds detected) | Detected by Wikipedia list | Detected by eBird list | Detected by lists | Detected by custom NER |
| #IndiAves | 2338 | 1286 | 609 | 605 | 639 | 1244 |
| #birdwatching | 3505 | 2062 | 863 | 912 | 944 | 1950 |
| #birdphotography | 6692 | 4470 | 1709 | 2334 | 2887 | 3442 |
There are obvious overlaps between the three sets of tweets. I suspect that there are tweets with bird names that the program could not detect. Given what we got, I immediately observed that around 51% of the birds are successfully detected by the curated lists. That’s not very efficient and this is the gap that can be filled by a simple AI component like the custom NER for bird detection over user-generated text content.
A solution to some issues:
When the program is not able to match any bird name, it seeks the custom NER to suggest. It cross-checks with eBird if the bird exists. This despite its resource intensiveness, solves some amount of the ambiguity and spelling mistakes.
- In this tweet, the NER model detects “grey wagtail”, and it changes to “gray wagtail” after searching on eBird. In this, the NER model detects “peacock” and changes it to “Indian Peafowl male”, and in this, the “breasted weaver” changes to “black breasted weaver”.
- When the user mentions a location, like in this case, it might be easier to say that it is a Eurasian Blue tit and not the African Blue Tit. But mentioning the location always does not help, for eg: when the NER model detects “musings sunbird” from a tweet, and eBird returns, “beautiful sunbird” (which is an actual bird). Just from the text, we are not able to understand which sunbird that is. It becomes a little difficult in these cases.
Immediate future work:
Ambiguity: As discussed in the previous section, ambiguity remains a major challenge to building a magical and flawless custom NER model.
Better predictions: From this tweet, the custom NER model detected “horn” as a bird name. When cross-checked with eBird, the program returned “horned lark” as the possible bird name. But in the original tweet, there is no bird.
Creation of a curated list: There are a few mistakes that are repetitive. We can make a list of those and change them to correct spellings during preprocessing. It requires time to build this.
Link to the Python Package: I did not make a package out of it.
Link to the Web Service: LINK.
Demo of the Web Service: Google Colab LINK
Would you want to collaborate?
Are you into NLP and birding? Would you like to collaborate? If yes, please send me an email. My email address is mailme@anirbansaha.com


- Olive Ridley Turtles at the Rushikulya Beach. - May 11, 2026
- Off-beat Wildlife Photography in India: 6 Species from Rushikulya to Dehing Patkai (2025) - December 30, 2025
- Hoolock Gibbons in India: The Singing Apes Fighting for Survival. - June 10, 2025